Expect emails from transcode-killer
Plex has the unhelpful feature (for us) of happily trying to "transcode" your video streams, to be as compatible as possible with every playback device, based on what it detects about your Plex client, and how fast it thinks your connection is. Some Plex apps also have conservative defaults, like limiting any remote playback to 720P!
This means, if you have a 80GB 4K HDR media file, and you try to watch it on a 720P, 2-channel chromecast, by default Plex will expend huge resources "transcoding" that beautiful, high-fidelity 🖼️ content to make it look like a soggy potato 🥔.
Transcodes can be extremely "expensive" in terms of CPU and GPU resources, and the end result is never as good as "DirectPlaying" the content. We strongly encourage users to store media at resolutions / qualities which they know their playback devices can play without transcoding. (the Radarr/Sonarr bundles have dual-aars for the purpose of managing multiple resolutions in a library, in case you're sharing with less-equipped friends). While we do enable hardware transcoding on Hobbits and larger packages, this is limited to 1080P and worse, since even 4K hardware transcodes are still far too resource-intensive.
So, we employ a "transcode-killer", a script which watches our nodes for resource-expensive transcodes, and.. kills them. From the user perspective, this looks like you're starting a stream, and then Plex stops with an error about "conversion failed", or "transcoder failed", depending on your particular client.
Today's glowup introduces a change to the killer - you can now see when it kills a transcode, by watching your Plex pod logs in Kubernetes Dashboard, or viewing its log directly in Filebrowser, at logs/plex/transcode-killer.log.
Notably, transcode-killer will also email you every time it kills an unwanted transcode, with details about the process and why it was killed, so you can hunt down those pesky friends-and-family who've not configured their Plex clients properly!
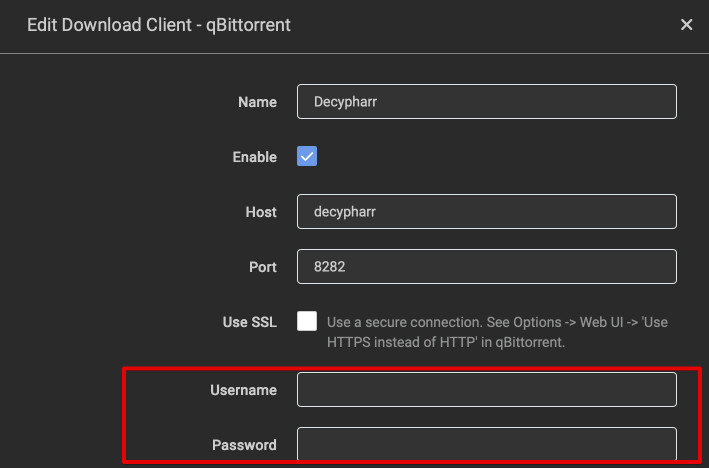
Decypharr on a diet
Over the past few days we've seen some instability for users, which seems to be tied to excessive bandwidth usage against their RD accounts (check yours at https://real-debrid.com/traffic). Turns out our rclone VFS cache settings were a little too manic, and it was consuming RD content in far larger "chunks" than necessary, especially for routine operations like Plex library scans.
The latest glowup applies a fix to normalize this, so you've noted unexplained large daily RD traffic summaries, the latest should improve this significantly. If you're a power-user, and you legitimately need > 300GB/day (potentially RD's limit for server-based users), then adding additional RD download tokens in Decypharr is a viable fix again.
Finally, it's no longer necessary to configure authentication for your Decypharr download client in the Aars - if you've got it correctly configured, it's harmless, but you'll see errors about validating aars in the decypharr logs if it's configured incorrectly, so if in doubt, you may as well remove it, like this: